OpenAI
Introducción
El propósito de este manual es detallar cómo configurar e integrar Qflow con OpenAI para permitir la interacción entre ambas plataformas, permitiendo utilizar los servicios de OpenAI, como la moderación de contenido y ChatGPT, desde Qflow.
OpenAI cuenta con las siguientes acciones:
Prerrequisitos
Es necesario contar con una cuenta de OpenAI. Si no tienes una, puedes crearla aquí.
Parámetro de aplicación
Para entablar la conexión es necesario contar con al menos un parámetro de aplicación (ver Parámetros de aplicación) que permita establecer la comunicación entre Qflow y OpenAI. Este parámetro puede ser creado desde la configuración de la tarea de servicio en Qflow, donde también se utiliza para establecer la comunicación entre Qflow y OpenAI. (ver Configuración de Conectores desde una Tarea de Servicio)
Para crear un parámetro de aplicación de OpenAI, se deben seguir los pasos que se detallan a continuación.
Parámetro de aplicación utilizando una API Key
Este tipo de parámetro de aplicación requiere lo siguiente:
API Key: Es la clave con la cual Qflow se autenticará en OpenAI para poder realizar las acciones disponibles.
Para obtenerla se deben seguir los siguientes pasos:
Dirigirse a la siguiente página, y de ser necesario iniciar sesión.
Una vez allí, hacer clic en el botón Create new secret key.
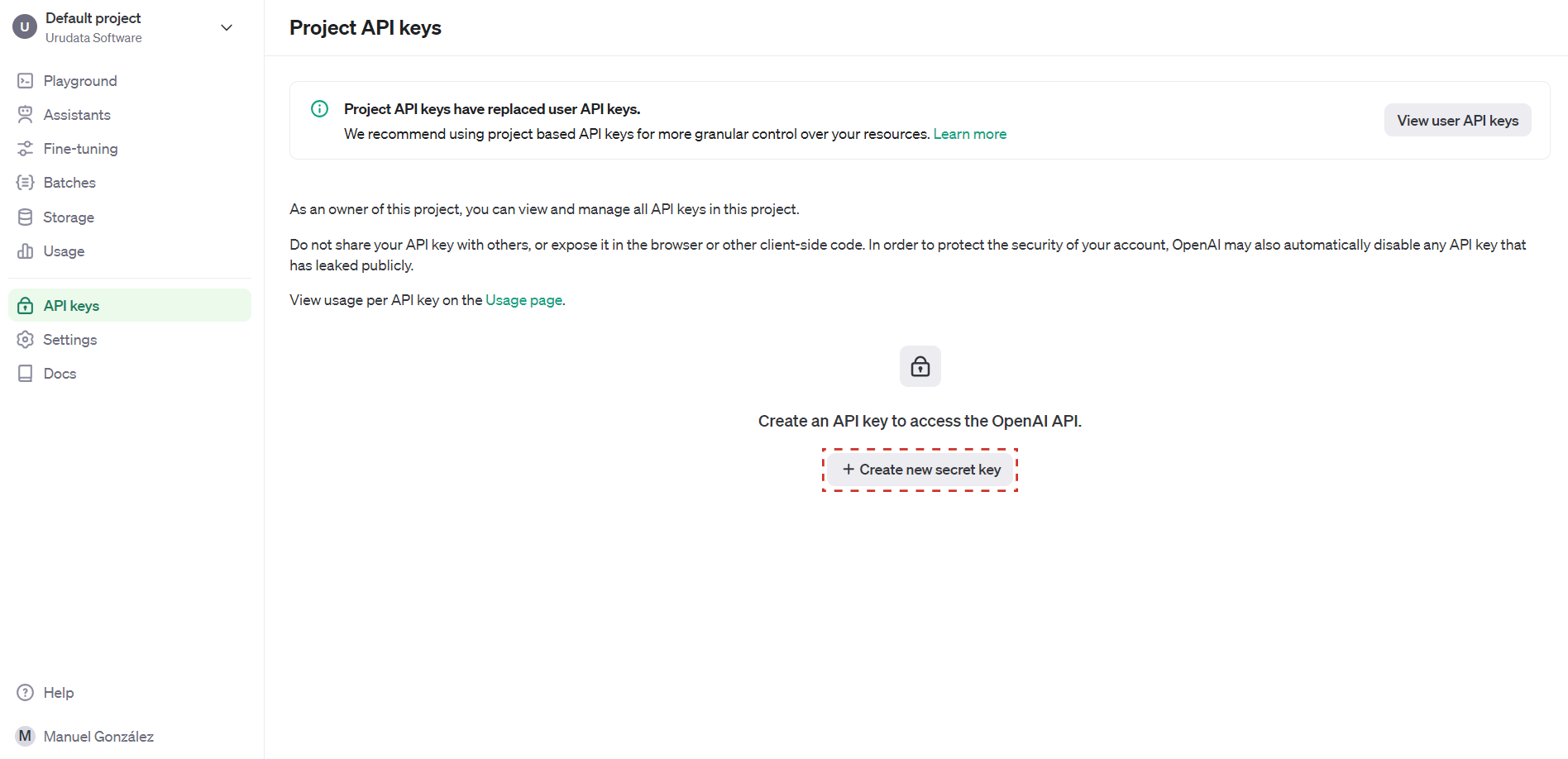
Figura 822 Panel de control de API Keys de OpenAI
Se abrirá una ventana en la que se podrán configurar los datos de la API Key. En el campo Name se puede asignar un nombre a la API Key, y en el campo Permissions se puede seleccionar el nivel de permisos que tendrá la API Key. Una vez configurados los datos, hacer clic en el botón Create secret key.

Figura 823 Creación de una nueva API Key
Una vez creada la API Key, se mostrará una ventana con la clave generada. Allí es importante copiar la clave con el botón Copy y guardarla en un lugar seguro, ya que no se podrá visualizar nuevamente. Es este el valor que se debe utilizar para el parámetro de aplicación en Qflow.
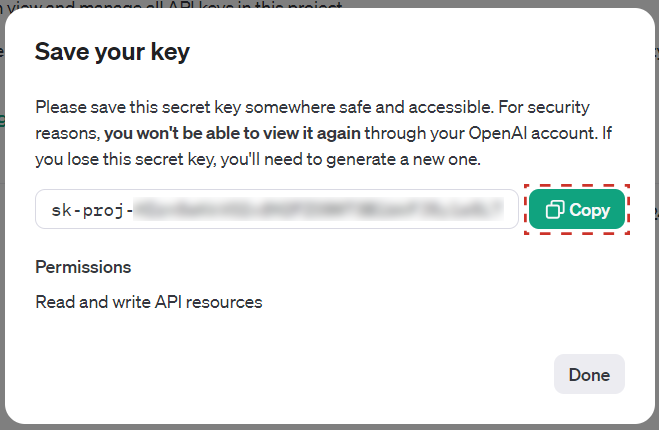
Figura 824 API Key generada
Una vez completados los pasos, será posible el uso de OpenAI con Qflow utilizando el parámetro de aplicación creado.
Acciones
Se pueden realizar las siguientes acciones con OpenAI:
Moderar contenido
Esta opción permite moderar contenido utilizando el servicio de moderación de OpenAI.
Entrada |
Descripción |
|---|---|
Texto |
Requerido. Texto que se desea moderar. |
Salida |
Descripción |
|---|---|
Resultado de moderación |
Devuelve “verdadero” si el texto fue marcado como contenido no apropiado, y “falso” si no lo fue. |
Categorías moderadas |
Devuelve un listado de las categorías en las que fue marcado el texto como contenido inapropiado, ordenados de mayor a menor puntuación, según que tan inapropiado fue considerado para esa categoría. Para ver todas las categorías posibles, ver la documentación de OpenAI. |
Puntuación de categorías |
Devuelve un texto JSON con la puntuación de cada categoría en la que fue moderado el text. Un valor más alto indica que el texto fue considerado más inapropiado para esa categoría. Un ejemplo de salida sería el siguiente: {
"sexual": 1.2282071e-06,
"hate": 0.010696256,
"harassment": 0.29842457,
"self-harm": 1.5236925e-08,
"sexual/minors": 5.7246268e-08,
"hate/threatening": 0.0060676364,
"violence/graphic": 4.435014e-06,
"self-harm/intent": 8.098441e-10,
"self-harm/instructions": 2.8498655e-11,
"harassment/threatening": 0.63055265,
"violence": 0.99011886,
}
|
Chat
Esta opción permite interactuar con el servicio de ChatGPT de OpenAI. Permite generar respuestas a partir de un mensaje de un usuario y un modelo de ChatGPT. También se pueden enviar mensajes de sistema para dar contexto o instrucciones sobre lo que se espera en la respuesta y mantener un hilo de conversación a través de múltiples mensajes.
Entrada |
Descripción |
|---|---|
Modelo |
Requerido. El modelo utilizado para generar la respuesta. Para conocer que modelos hay disponibles haga click aquí. |
Formato de respuesta |
El formato en el que se desea recibir la respuesta. Los formatos disponibles son: |
Prompt de sistema |
Texto que se utilizará como prompt para generar la respuesta. Puede servir para dar contexto o presentar instructiones sobre lo que se espera en la respuesta. |
Mensaje del usuario |
Requerido. El mensaje que se desea enviar a ChatGPT para generar la respuesta. |
Historial de mensajes en formato JSON |
Historial de la conversación en formato JSON que se utilizará para generar la respuesta. Puede servir para dar contexto
o mantener un hilo de conversación a través de múltiples mensajes. Es una lista de objetos JSON, donde cada objeto tiene
dos campos: [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the capital of France?"},
{"role": "assistant", "content": "The capital of France is Paris."},
{"role": "user", "content": "What is its population?"}
]
|
Penalización de frecuencia |
Número entre -2.0 y 2.0. Los valores positivos penalizan los nuevos tokens en función de su frecuencia existente en el texto hasta el momento, disminuyendo la probabilidad de que el modelo repita la misma línea textualmente. Más información. |
Número máximo de tokens |
El número máximo de tokens que se permitirán en la respuesta generada. Si no se especifica, se utilizará el máximo implícito del modelo. |
Cantidad de respuestas |
Número de respuestas que se desean generar. Por defecto, se generará una sola respuesta. Ten en cuenta que se te cobrará por el total de tokens generados en todas las respuestas. |
Penalización por presencia |
Número entre -2.0 y 2.0. Los valores positivos penalizan los nuevos tokens en función de si aparecen en el texto hasta el momento, aumentando la probabilidad del modelo de hablar sobre nuevos temas. Más información. |
Temperatura |
Número entre 0 y 2. Se recomienda utilizar este campo o “Top P”, pero no ambos. Valores más altos harán que la salida sea más aleatoria, mientras que valores más bajos la harán más enfocada y determinística. Más información. |
Top P |
Número entre 0 y 1. Es una alternativa al muestreo con temperatura, llamada muestreo de núcleo, donde el modelo considera los resultados de los tokens con la probabilidad de masa top_p. Así que 0.1 significa que solo se consideran los tokens que comprenden el 10% superior de la masa de probabilidad. Se recomienda utilizar este campo o “temperatura”, pero no ambos. Más información. |
Salida |
Descripción |
|---|---|
Respuestas |
Requerido. Lista de respuestas generadas por ChatGPT. En caso de haberse solicitado más de una respuesta, se devolverán todas las respuestas generadas. |
Historial de mensajes en formato JSON |
Historial de la conversación en formato JSON con todos los mensajes, incluyendo los generados por ChatGPT. Este campo puede ser usado como entrada en una llamada futura para mantener un hilo de conversación. Por ejemplo, suponiendo que en la entrada se envió el historial de mensajes, un prompt de sistema y se solicitaron dos respuestas, la salida podría ser la siguiente: 1 [
2 {"role": "system", "content": "You are a helpful assistant."},
3 {"role": "user", "content": "What is the capital of France?"},
4 {"role": "assistant", "content": "The capital of France is Paris."},
5 {"role": "system", "content": "You are a lying assistant."},
6 {"role": "user", "content": "What is the capital of France?"},
7 {"role": "assistant", "content": "The capital of France is Madrid."},
8 {"role": "assistant", "content": "The capital of France is London."}
9 ]
En el ejemplo anterior, se puede ver que el historial de mensajes incluye los mensajes pasados (de la línea 2 a la 4), el prompt de sistema (línea 5), el mensaje del usuario (línea 6) y las respuestas generadas por ChatGPT (líneas 7 y 8). Para ver más detalles sobre el formato de este campo, ver más arriba. |
Motivo de finalización |
Motivo por el cual se detuvo la generación de respuestas. Puede ser |
JSON de respuesta |
Devuelve el JSON de respuesta tal cual lo devuelve OpenAI. Para más información, ver la documentación de OpenAI. |
Uso total |
Devuelve el uso total de tokens. Incluye tanto los tokens de entrada como los tokens generados en las respuestas. |