OpenAI
Introduction
The purpose of this manual is to detail how to configure and integrate Qflow with OpenAI to allow interaction between both platforms, allowing the use of OpenAI services, such as content moderation and ChatGPT, from Qflow.
OpenAI has the following actions:
Prerequisites
You need to have an OpenAI account. If you don’t have one, you can create one here.
Application parameter
To establish the connection, it is necessary to have at least one application parameter (see Application Parameters) that allows communication between Qflow and OpenAI. This parameter can be created from the service task configuration in Qflow, where it is also used to establish communication between Qflow and OpenAI. (see Connector Configuration from a Service Task)
To create an OpenAI application parameter, follow the steps detailed below.
Application parameter using an API Key
This type of application parameter requires the following:
API Key: It is the key with which Qflow will authenticate with OpenAI to be able to perform the available actions.
To obtain it, follow these steps:
Go to the following page, and if necessary, log in.
Once there, click on the Create new secret key button.
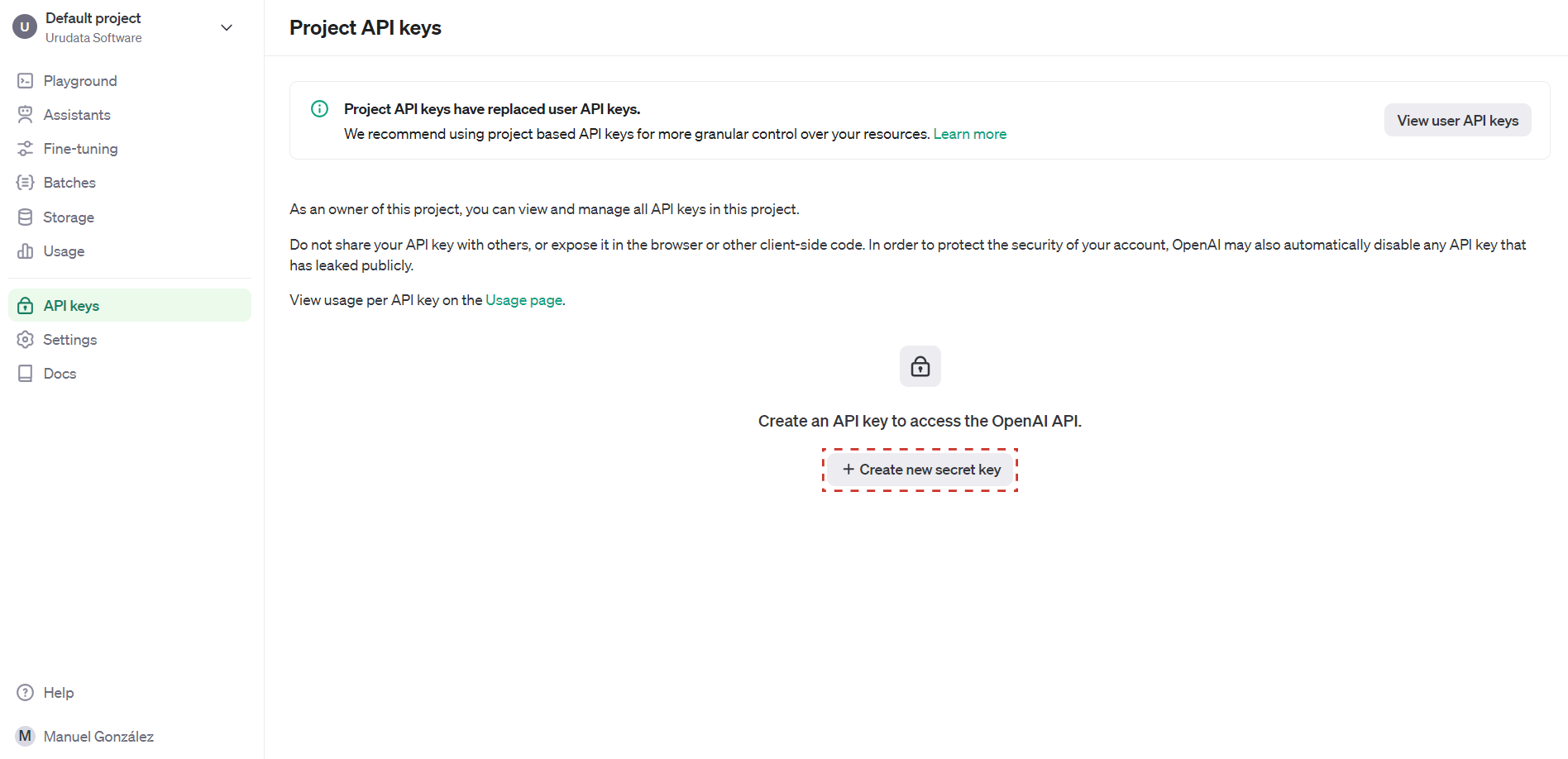
Fig. 822 OpenAI API Keys control panel
A window will open where you can configure the API Key data. In the Name field you can assign a name to the API Key, and in the Permissions field you can select the level of permissions that the API Key will have. Once the data is configured, click on the Create secret key button.

Fig. 823 New API Key creation
Once the API Key is created, a window will appear with the generated key. It is important to copy the key with the Copy button and save it in a safe place, as it will not be visible again. This is the value that must be used for the application parameter in Qflow.
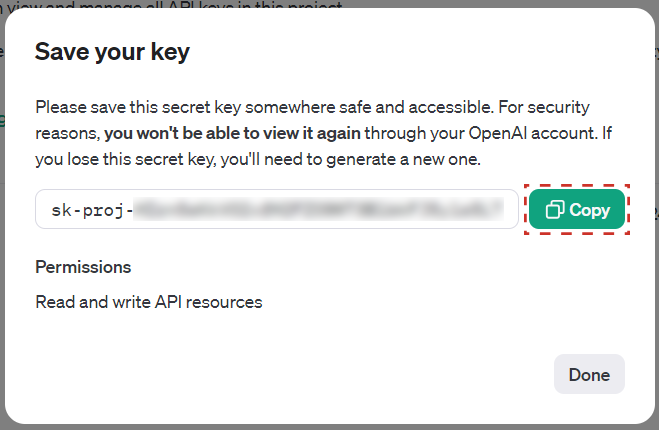
Fig. 824 Generated API Key
Once the steps are completed, it will be possible to use OpenAI with Qflow using the created application parameter.
Actions
It is possible to perform the following actions with OpenAI:
Moderate content
This option allows content moderation using the OpenAI moderation service.
Input |
Description |
|---|---|
Text |
Required. Text to be moderated. |
Output |
Description |
|---|---|
Flagged |
Returns ‘true’ if the text was flagged as inappropriate content, and ‘false’ if it was not. |
Flagged categories |
Returns a list of the categories for which the text was flagged as inappropriate content, sorted from highest to lowest score, according to how inappropriate it was considered for that category. To see all possible categories, go to OpenAI's documentation. |
Category scores |
Returns a JSON text with the score of each category for which the text was moderated. A higher value indicates that the text was considered more inappropriate for that category. A possible output would be the following: {
"sexual": 1.2282071e-06,
"hate": 0.010696256,
"harassment": 0.29842457,
"self-harm": 1.5236925e-08,
"sexual/minors": 5.7246268e-08,
"hate/threatening": 0.0060676364,
"violence/graphic": 4.435014e-06,
"self-harm/intent": 8.098441e-10,
"self-harm/instructions": 2.8498655e-11,
"harassment/threatening": 0.63055265,
"violence": 0.99011886,
}
|
Chat
This option allows you to interact with OpenAI’s ChatGPT service. It allows you to generate responses from a user’s message. You can also send system messages to provide context or instructions on what is expected in the response and maintain a conversation thread across multiple messages.
Input |
Description |
|---|---|
Model |
Required. The model used to generate the response. To find out which models are available click here. |
Response format |
The format in which you want to receive the response. The available formats are: |
System prompt |
Text that will be used as a prompt to generate the response. It can be used to provide context or provide instructions on what is expected in the response. |
User message |
Required. The message you want to sent to ChatGPT to generate the response. |
Chat history in JSON format |
Chat history in JSON format that will be used to generate the response. It can be used to provide context or maintain a conversation thread across multiple messages. It is a list of JSON objects, where each object has two fields: [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the capital of France?"},
{"role": "assistant", "content": "The capital of France is Paris."},
{"role": "user", "content": "What is its population?"}
]
|
Frequency penalty |
Number between -2.0 and 2.0. Positive values penalize new tokens based on their existing frequency in the text so far, decreasing the probability that the model will repeat the same line verbatim. More information. |
Maximum number of tokens |
The maximum number of tokens allowed in the generated response. If not specified, the implicit maximum of the model will be used. |
Number of choices |
Number of responses you want to generate. By default, a single response will be generated. Keep in mind that you will be charged for the total number of tokens generated in all responses. |
Presence penalty |
Number between -2.0 and 2.0. Positive values penalize new tokens based on whether they appear in the text so far, increasing the model’s probability of talking about new topics. More information. |
Temperature |
Number between 0 and 2. It is recommended to use this field or ‘Top P’, but not both. Higher values will make the output more random, while lower values will make it more focused and deterministic. More information. |
Top P |
Number between 0 and 1. It is an alternative to temperature sampling, called core sampling, where the model considers the results of tokens with the top_p mass probability. So 0.1 means that only the tokens that make up the top 10% of the probability mass are considered. It is recommended to use this field or ‘temperature’, but not both. More information. |
Output |
Description |
|---|---|
Responses |
Required. List of responses generated by ChatGPT. If more than one response has been requested, all the responses generated will be returned. |
Chat history in JSON format |
Chat history in JSON format with all messages, including those generated by ChatGPT. This field can be used as input in a future call to maintain a conversation thread. For example, assuming that the message history was sent in the input, a system prompt was sent, and two responses were requested, the output could be as follows: 1 [
2 {"role": "system", "content": "You are a helpful assistant."},
3 {"role": "user", "content": "What is the capital of France?"},
4 {"role": "assistant", "content": "The capital of France is Paris."},
5 {"role": "system", "content": "You are a lying assistant."},
6 {"role": "user", "content": "What is the capital of France?"},
7 {"role": "assistant", "content": "The capital of France is Madrid."},
8 {"role": "assistant", "content": "The capital of France is London."}
9 ]
In the previous example, you can see that the message history includes past messages (from line 2 to 4), the system prompt (line 5), the user message (line 6) and the responses generated by ChatGPT (lines 7 and 8). For more details on the format of this field, see above. |
Finish reason |
Reason why the response generation was stopped. It can be |
Response JSON |
Returns the response JSON as returned by OpenAI. For more information, see OpenAI's documentation. |
Total usage |
Returns the total token usage. It includes both the input tokens and the tokens generated in the responses. |